计算机硬件结构
计算机发展路程
图灵机
计算机的起源,是从图灵机开始的,所谓图灵机,其实是用机器来模拟人们用纸笔进行数学运算的过程。
它的基本组成是一条纸带加一个读写头:
纸带:有多个连续格子组成,每个格子存放不同字符,即后来的数据或者程序
读写头:读取纸带上的内容
其中,读写头内部还包含存储单元,控制单元,以及运算单元
冯诺依曼模型
冯诺依曼模型是在图灵机的基础上,约定以二进制进行计算和存储。 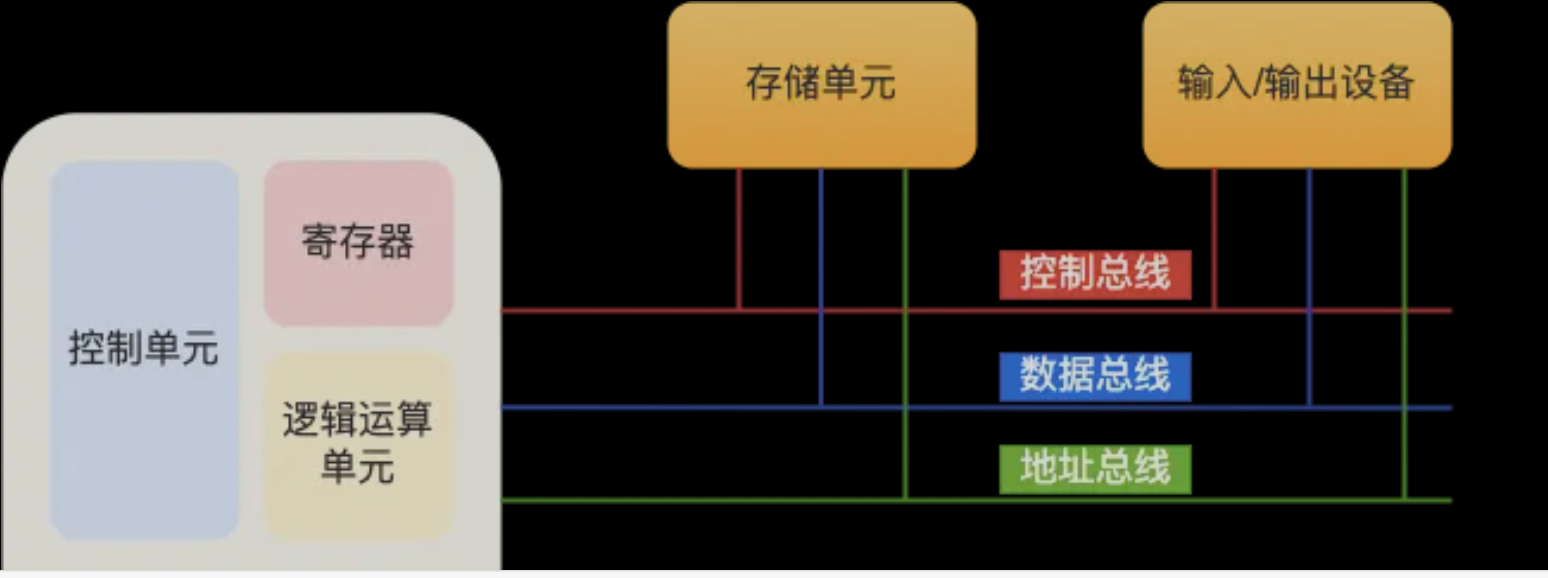
其基本组成为:
运算器:运算单元
控制器:负责cpu工作
存储器:cpu内部的寄存器与外部的存储设备,存储区域是线性的,基本单位为字节(byte),一字节为8bit,每一字节都对应一个内存地址。
寄存器又包含:通用寄存器(用于存放进行运算的数据),程序计数器(用于存放下一条执行的指令),指令寄存器(存放当前执行的指令)
输入输出设备:
总线:分为地址总线,数据总线,控制总线。地址总线用于指定访问地址,控制总线控制命令,数据总线传输数据
- 32位cpu与64位cpu
1条地址总线最大能操作2^1个地址,那么cpu最大操作4GB地址,需要32位地址总线,此时的cpu就是32位cpu。
当需要运算超过32位的数字时,64位cpu显示出优势。
而对于32位的软件想在64位的计算机上运行时,可以靠兼容软件实现,而反过来,不可实现,因为32位计算机无法读取存储64位的指令。
程序执行过程
- cpu读取程序计数器里的值后,控制单元调用地址总线指向内存地址,接着通知内存准备数据,并通过数据总线传入cpu,随后将该指令存入指令寄存器中;
- 程序计数器自增,例如32位自增4个字节,因为其指令为4个字节;
- cpu通过确定指令寄存器里的指令类型和参数,分配指令执行单元,包含控制单元和逻辑运算单元。
现在cpu通常执行四个阶段(流水线技术):fetch(取得指令)— Decode(指令译码) — Execution(执行指令) — Store(数据回写)
指令
指令由一串二进制数字机器码组成,不同指令对应不同的汇编语言和机器码;
从功能角度划分:
- 数据传输类型:store/load/mov
- 运算类型: 加减乘除
- 跳转类型:if-else
- 信号类型: 如中断指令trap
- 闲置类型:nop 执行后cpu空转一周期
程序运行速度:
其中CPI为每条指令的平均时钟周期数。
因此想提升速度,可以从下面入手:
指令数:主要靠编译器优化
cpi: 靠流水线技术
时钟周期时间:取决于计算机硬件
存储器层次结构
cpu内部的寄存器用于将正在运行的数据存储,但容量较小,除了它,cpu内部还有cpu Cache,cpu Cache 中文名为高速缓存,
通常分为 L1,L2 , L3 三层,L1可以类比为短期记忆,L2/L3 则可以类比为长期记忆。
cpu外部,有内存和硬盘,整体而言,存储器可以分为: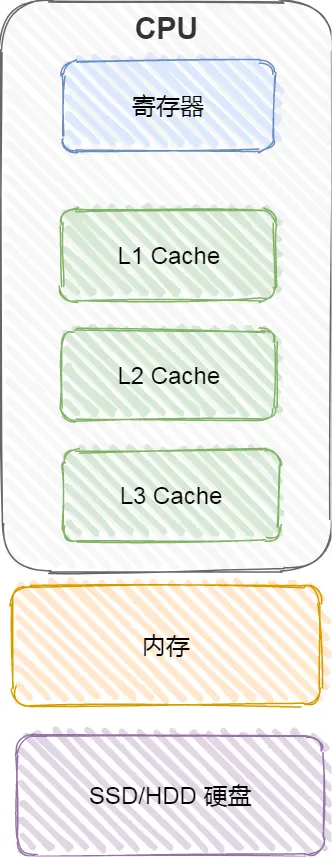
寄存器:速度最快,要求在半个cpu周期内完成读写
CPU Cache: 使用SARM的芯片,即断电数据会丢失,再往下细分有:
- L1高速缓存:距离CPU最近,访问速度接近寄存器,速度在2~4个时钟周期,常分为指令缓存和数据缓存。
- L2高速缓存:速度在10~20个时钟周期。
- L3高速缓存:速度在20~60个时钟周期,大小也更大一些,且多个CPU核共享。
内存:采用DRAM,速度在200~300个时钟周期内,靠不断刷新才能保证数据不丢失。
SSH/HDD硬盘:固态硬盘和机械硬盘。
每个存储器只和相邻的一层存储器进行数据传输,ssh比hhd快70倍,内存比hhd快10w倍,L1Cache比hhd快1000w倍。
CPU在读取数据时,首先读取寄存器里的数据,寄存器内没有想要的数据,则读取Cache里的数据,读取Cache时,Cache内部划分为若干个
内存块(CPU Cache Line),每一个内存块中存有外部存储信息的地址信息,通常为取模运算得出来的,为了区分多个数取模后的结果相同,
Cache里面设置了组标记, 除此之外,被划分的内存块(CPU Cache Line)还有实际存放的数据,以及有效位(用于判断存储数据是否有效)
CPU为了能准确的取出想要的数据,就在内存地址内设置了偏移量。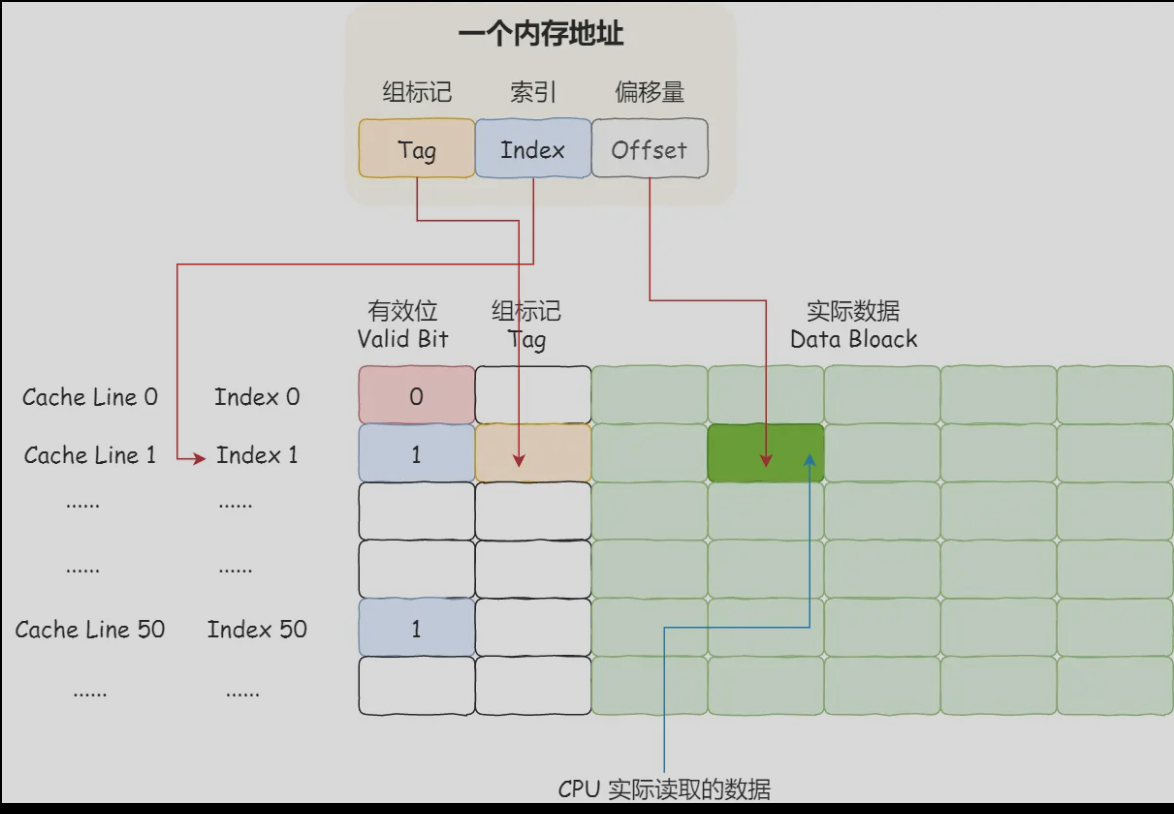
那么如何提升CPU跑代码的速度:
应当从数据缓存命中率和指令缓存命中率考虑,
- 对于数据缓存命中率,cpu读取数据时是按照内存条读取,即为一行一行的读取,而且cpu会多读取几个数。
- 指令缓存命中率则可以靠分支预测器将预测将要运行的数据提前加载到指令缓存中。
- 对于提升多核CPU的缓存命中率,可以将线程绑定到某一个CPU核心上。
CPU缓存一致性
Cache 写回内存方法:
写直达:判断数据是否在cache里面,在则更新,不在则直接写入内存。
写回:在写直达的基础上,只有cache block被修改时才需要写道内存中,因此每执行写操作,就会标记cache block为脏,当下一次访问该block时,
才会存入到内存中。
写回: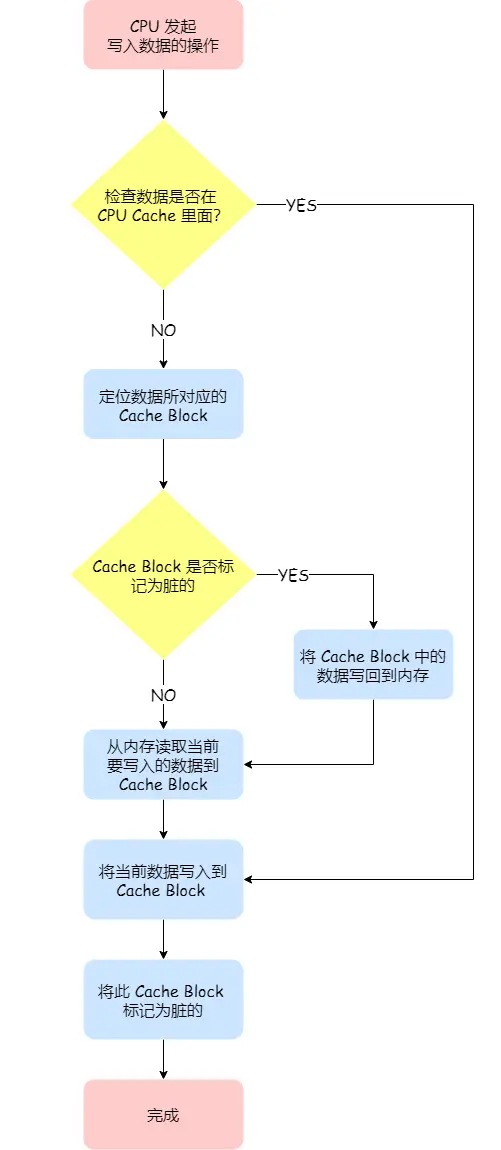
缓存一致性问题
cpu有多个核心,核心A在处理变量i时,核心B读取变量i会发现读取数据不一致,为解决这种问题需要保证下面2点:
- 写传播: 一个核心更新必须保证传播到其他核心。
实现方式:总线嗅探,即某个核心更改数据时,会通过总线告知其他核心,因此需要保证cpu时刻监听总线。 - 事务串行化:某个核心对数据的操作顺序,在其他核心看来应该是一样的。
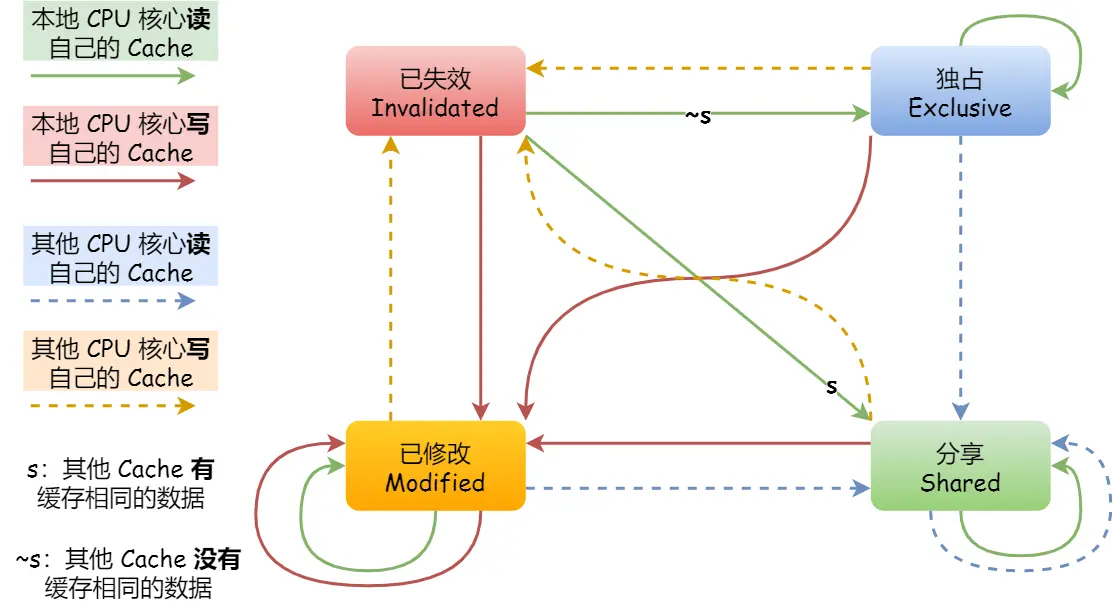
实现方式:MESI协议,基于总线嗅探,靠四个状态分别为:已修改,已失效,共享,独占,其中共享和独占状态表示已经缓存一致了,
独占是指数据只存储在一个cpu核心里,需要修改可以不通知其他核心,当其他核心要读取这个数据时,改状态为共享,共享指数据
存储在多个核心里,某核想要继续修改,则广播其他核心更改状态为已失效,自己更改为独占。已修改即为标记为脏。
MESI协议的状态可用有限状态机表示:
CPU如何执行任务
CPU读取数据
cpu在读取数据时,会发生伪共享。
伪共享:是指cpu内部的多个核心在取数据时,即便处理的数据不同,但是各自处理的数据又互相相连,从而导致CPU Cache 失效的现象。
避免伪共享的方法:
- 在Linux内核中存在 _cacheline_aligned_in_smp 宏定义,解决原理是将相邻的两个数据拆开为两块,各自被各自核心读取。
- java里在应用层定义7个long类型的变量进行前置填充,这样要处理的数据就会被分割留在不同的两块中。
CPU选取线程
linux里靠调度器进行任务的调度,调度器对应的调度类又分为三种,其中Deadline和Realtime这两个调度类都应用于实时任务,作用有:
- SCHED_DEADLINE:按照deadline进行调度。
- SCHED_FIFO: 按照先来先服务原则。
- SCHED_RR:每个任务有相同时间片,用完排在队伍后面。
另外一个是Fair调度类,用于普通任务:
- SCHED_NORMAL:普通任务使用策略。
- SCHED_BATCH:后台任务调度策略。
对于普通任务:linux内部实现了完全公平调度:即给每一个任务分配虚拟运行时间,一个任务运行越久,分配的运行时间越大,cpu优先选择运行时间少的。
这些任务又按照虚拟运行时间长短用红黑树来排序成任务队列。
如果想优先执行某些任务,可以通过设置优先度来进行。
什么是软中断
啥是中断
操作系统接收中断请求后打断正在执行的进程然后调用中断处理程序来响应请求。中断处理程序又分为上下两个部分:
- 上半部分直接处理硬件请求,即为快速处理响应中断,叫做硬中断;
- 下半部分由内核触发,主要工作为从内存中找到网络数据,并按照网络协议栈对数据进行处理,最后把数据送给应用程序。称为软中断。

DragonBo
这一切还是精彩