黑马点评
在即将完成某项功能时,先将流程图设计出来,然后按照流程图一步一步设计。
## 项目导入
- 项目导入时,数据库需要更改,数据库的url处需要添加所需库对应的schema。
短信登录
短信登录功能实现由三部分组成,发送短信验证码,短信验证码验证,身份校验。
短线验证码
这部分主要是验证用户手机号是否规范,规范则生成验证码并调用云服务将验证码以短信的形式发送给用户,
验证码的生成可以通过糊涂包里的随机生成函数实现,云服务可以调用阿里云实现,然后将验证码保存到session中。
短信验证码验证
这部分是对验证码的验证,首先要做的是将session里的验证码拿出来与前端返回的验证码进行比较,正确则再判断用户是否为
新用户,新用户则创立新的用户对象并保存到表中,然后将该用户保存在session中。
身份校验
用户登录后访问其他功能时,浏览器需要判断该用户是否存在,这就需要身份验证,而身份验证的位置就很关键,如果设置在每个将要访问的功能处,就会
造成代码的重复,所以设置了拦截器,放置在server层的最前端,验证成功则放行,随后可以访问其他功能。
- 拦截器内部
- 就是要实现的功能–身份验证,首先从session中获取到用户,然后查表判断该用户是否存在,存在则放行,并将用户对象保存到threadlocal中,
这里的threadlocal就是每个线程自己的存储空间,线程结束,这里面的值自动销毁。 - 拦截器注册,需要新建立一个环境完成注册,注册拦截器时,可以选择不拦截哪些网页。
- 就是要实现的功能–身份验证,首先从session中获取到用户,然后查表判断该用户是否存在,存在则放行,并将用户对象保存到threadlocal中,
Redis提升
session共享问题:多台tomcat不共享session空间,当请求切换到其他tomcat时会导致数据丢失。
为了解决这一问题,引出了redis,这样不同的tomcat都要从redis中取用户信息。同时还解决了
sessio的不安全的问题。
具体提升:
- 原本需要保存到session中的数据保存到了redis中,提高了安全性。
- 在短信验证码验证部分,生成了token作为查询redis里数据的key,减少了用户信息泄露的风险。生成的token返回给前端,等
到身份验证时,从前端处获取token,从而查询到用户信息,完成用户身份验证,而且token还有生效时间的设置,设置时间为30分钟
,在生成并存入redis时设置,身份验证时会进行刷新。 - 对于不用进行身份验证就能访问的网页,会存在token失效的情况,所以设置两个拦截器,第一个拦截器负责刷新,第二个拦截器则负责拦截。
细节小点
- 不是spring创建的对象不能使用注入注解来注入,应该通过构造函数来完成导入,
redis缓存
缓存概念
缓存就是一种具备高效读写能力的数据暂存区域。
- 作用:
- 降低后端负载
- 提高服务读写响应速度
- 成本:
- 开发成本
- 运维成本
- 一致性问题
缓存策略
- 三种策略:
- 内存淘汰策略:redis自带的淘汰机制(可联想到计算机缓存回收策略)
- 过期淘汰:利用expire命令给数据设置过期时间
- 主动更新:主动完成数据库与缓存同时更新
- 策略选择:
- 低一致性:内存淘汰
- 高一致性:主动更新为主,过期淘汰兜底
-主动更新方案: - cache aside : 缓存调用者在更新数据库的同时完成对缓存的删除(这里还有更好的策略,延迟双删)
- read/write through :缓存与数据库集成一个服务,服务保证两者一致性,对外只暴露API接口,调用者调用API。
- write back: 缓存调用者的CRUD都针对缓存完成。有独立线程完成将缓存写入数据库。
- cache aside模式选择:
- 更新缓存和删除缓存的选择:删除缓存本质就是延迟更新,没无效更新,线程安全问题相对较低。
- 先操作数据库还是缓存: 先更新数据库,再删缓存安全概率更低,当然前提是满足原子性。
- 如何确保原子性: 单体系统–事务机制 ,分布式系统:利用分布式事务机制。
项目具体实现
查询数据时,先查询缓存,缓存命中则返回,未命中则查询数据库,数据库有则写入缓存,然后返回结果。
修改数据时,先更新数据库,再删除缓存,保证两者原子性。
缓存穿透
- 产生原因:
- 要查询的数据既没有在数据库中,也没有在缓存中,请求全部打到了数据库上。
- 解决方案:
- 缓存空对象:对于不存在的数据也在缓存中缓存,但值设置为空,并设置了一个较短的TTL时间。
- 布隆过滤: 利用布隆过滤算法,布隆过滤器由位数组和一系列随机映射函数组成,初始状态下,位数组设置为0,然后利用多个独立的哈希函数计算每一个要加入
过滤器的元素,计算出的位置都设置为1,当查询一个元素是否存在时,同样使用相同的哈希函数计算位数组中的位置,并检查是否全为1,是则可能存在,不是则一定不存在。
缓存雪崩
- 产生原因:
- 大量key突然同时失效或者redis服务器宕机,请求全部打到数据库,带来压力。
- 解决方案:
- 设置随机过期时间。
- 利用redis集群提高服务可用性
缓存击穿
-产生原因:
- 热点key失效过期,重建耗时较长,这段时间大量请求落到数据库
- 解决方案:
- 互斥锁:
- 给缓存重建加锁,确保重建过程只有一个线程执行,其他线程等待,
- 好处是实现简单,但是等待时间过长性能就下降了,而且有死锁的风险。
- 实现是靠setnx函数获取锁的。
- 逻辑过期
- 热点key缓存永不过期,而是设置逻辑过期时间,查询到该数据时,先判断逻辑过期时间,然后来决定是否重建缓存,重建缓存
也是通过互斥锁保证单线程执行,重建缓存利用独立线程异步执行,其他线程不需等待,直接查询到旧数据并返回。 - 优点就是性能好
- 缺点就是不保证一致性,且有额外内存消耗。
- 实现:重新创建实体对象,并将过期时间加入,创建线程池获取线程异步执行缓存重建
- 热点key缓存永不过期,而是设置逻辑过期时间,查询到该数据时,先判断逻辑过期时间,然后来决定是否重建缓存,重建缓存
- 互斥锁:
工具类封装
要点就是泛型的使用,基本实现步骤就是将原来具体的函数中具体的数据类型改的宽泛一些,对于需要调用者调用的函数,可以放在函数所需参数中

秒杀优惠卷
超卖问题
超卖问题是指在多线程的情况下,一个线程查询库存充足但还未扣减库存时,另外的线程也查询了库存,而线程1已经将库存扣减完了
但是另外的线程因为已经做过判断,所以还在对库存进行扣减,这样就造成了超卖问题。及就是多个线程共享资源,扣减资源的动作之间
多线程会穿插。
解决超卖问题
- 乐观锁:关键就是判断前后查询的数据是否改变,这里使用了cas算法,比较前后查询到的库存数量,当库存数量等于之前所查询的数量时才进行库存的扣减,也就是将库存数量作为
扣减的条件。- 但是失败率很高,条件过于苛刻,所以优化的地方就是将原来前后库存数量必须相等的条件改为库存大于0
- 悲观锁: 简单但是性能一般,不如乐观锁的不上锁。
实现一人一单
同样存在多线程并发操作穿插问题,解决办法依然是加锁
- 加悲观锁:但需要注意的地方是spring事务注释功能的实现是在代理对象下实现的,所以锁住了一个事务,就必须拿到它的代理对象,
这个可以通过aop生成一个代理对象,并将要实现的事务的函数加入到代理对象中
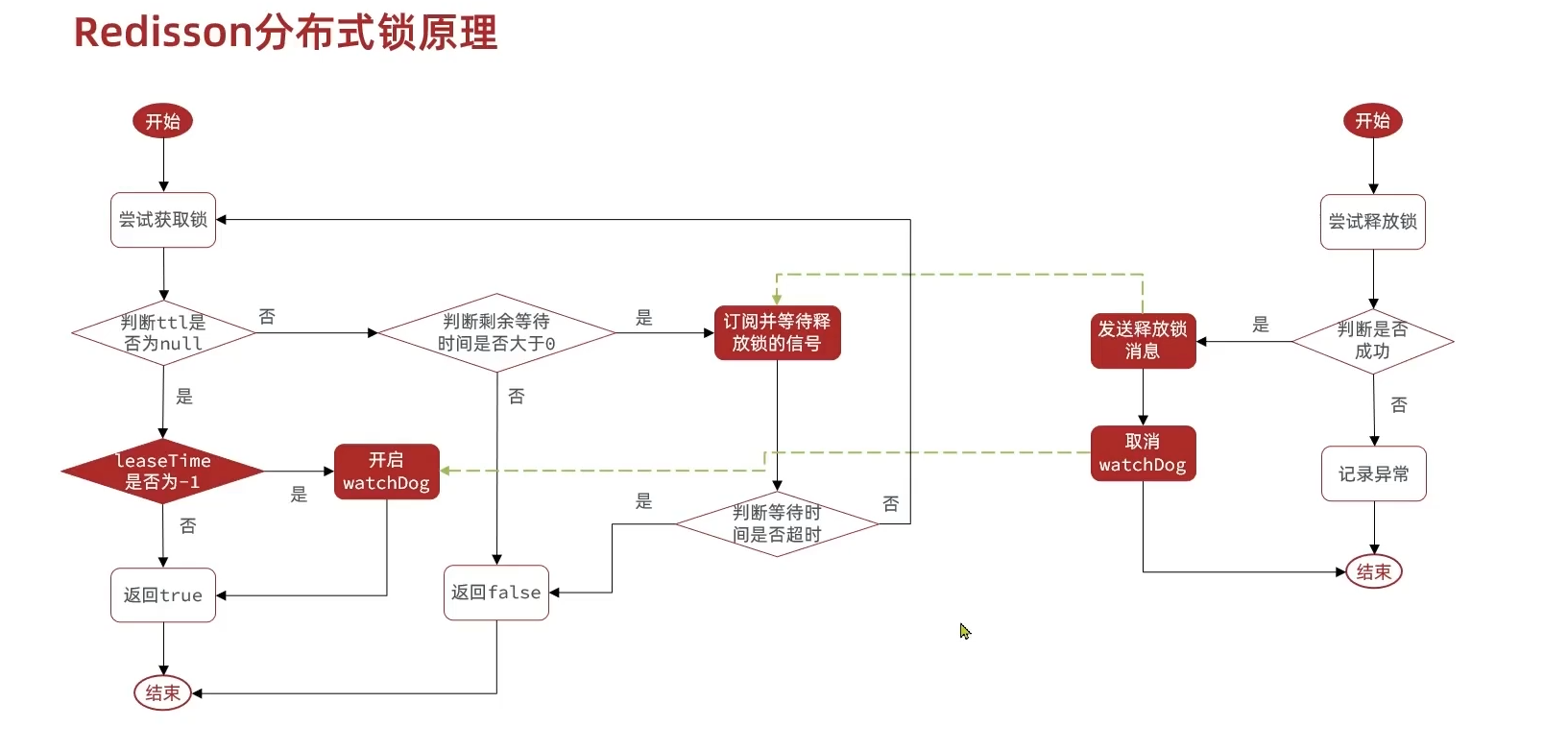
分布式锁
单线程内,悲观锁足够解决问题,但是多个线程下,锁监视器不是同一个,而是各自都有,就导致锁不住了,
所以需要多个线程可见的锁监视器,就是分布式锁:
分布式锁是满足分布式系统或集群模式下多进程可见并且互斥的锁,他是高可用的,
基于redis的分布式锁
- setnx:
- 不可重入:同一个线程无法多次获取同一把锁
- 不可重试:获取锁只尝试一次就返回false,没重试机制
- 超时释放:业务执行耗时较长会导致锁释放,存在安全隐患
- 增加uuid,在删除锁之前判断uuid是否一致,一致再删除,保证不误删其他的锁
- 但是如果不保证原子性,同样会误删其他的锁。
- 主从一致性
- setnx进一步优化:
-lua脚本:能保证原子性,通过exeuct调用脚本 - redisson:
- 可重入:内部是hash结构能够记录获取锁的对应的线程以及对应的获取次数
- 可重试:获取失败时,subscribe一个其他的线程id,当这个线程释放了锁发出信号就会被捕捉。当然也有时间限制,限制为等待时间
不超过时间限制。 - 看门狗机制:没设置最大超时时间,默认为30秒,并且会自动续约,实现方式就是递归,过期重新调用自己完成时间的更新。
直到释放锁的时候,就会取消更新。
- multilock:
- 解决主从一致的问题,建立多个redis节点,这几个节点都申请锁,最后再将这几个申请到的锁连起来,这样即使其中一个节点宕机
也会保证锁不会失效,即其他线程拿不到这个锁。
- 解决主从一致的问题,建立多个redis节点,这几个节点都申请锁,最后再将这几个申请到的锁连起来,这样即使其中一个节点宕机
秒杀优化
因为一个线程需要多次的io操作,所以会导致性能下降,解决的办法是异步下单,其实就是第一步判断用户是否有下单资格并进行库存预减
,然后将订单的创建交给另一个线程,而客户已经收到下单成功的反馈。 用到的工具就是消息队列。
- 第一步: 在lua脚本中编写判断用户是否有下单资格,判断完成后则返回对应信息。
- 第二步:将对应的信息做判断,没有则返回给用户失败的信息,有则放入消息队列中,然后返回给用户订单id也就是订单成功信息。
- 第三步: 创建一个新线程,新线程从消息队列中读取消息订单,然后执行订单的创建。
消息队列的选择
- 使用jdk内部的阻塞队列:好用但是容易溢出
- 基于redis实现消息队列:
- list,pubmed
redis的基于stream消息队列的XREADGROUP命令
特点就是:
- 消息可回溯
- 多个消费者争抢,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制
它的实现是先在redis中创建消息队列,然后可以直接在lua脚本中调用redis往里存放消息,然后读取时也是通过redis终端调用read函数
后在其中创建消费者对象,然后初始化读取的操作,之后可以将读取到的消息解析然后完成下单,读取异常的消息会被放入pendinglist中,这样
如果判断读取异常,就继续读取pendinglist中的消息,直到读取完为止。

点赞及其显示
点赞
根据用户id查询相关信息并存入blog实体类中。点赞的用户存放在zset中,每次进行点赞动作时,需要判断该用户是否在zest中,
在的话,点赞动作为取消点赞,调用数据库实现点赞数量的相减,相反则相加,显示top的点赞用户,就需要zset里的排序功能。
这里需要注意的是in功能查询需要指定对应的排序顺序。

DragonBo
这一切还是精彩